

Aufbau eines Metrik-Backends (Zeitreihen-DB) mit PostgreSQL und Rust
.avif)



Bei ilert profitieren Kunden bereits von unseren leicht einzurichtenden privaten oder öffentlichen Statusseiten und automatisch generierten SLA-Uptime-Graphen für ihre Geschäftsdienste. Wir haben uns jedoch entschieden, das Thema Grafiken mit benutzerdefinierten Metriken etwas weiter voranzutreiben. Mit ilert Metrics können Kunden zusätzliche Geschäftsdaten und Einblicke in ihre Dienste auf ihren Statusseiten präsentieren.
Um Metriken (Zeitreihen) zu erfassen, zu speichern, abzufragen und zu aggregieren, haben wir uns die Lösungen auf dem Markt angesehen, insbesondere die Lösungen der Cloud-Anbieter. Letztendlich entschieden wir uns jedoch, unsere eigene Zeitreihendatenbank zu modellieren, unter Verwendung der Tools, die wir bereits kennen und auf die wir uns verlassen, während wir sie perfekt auf unseren spezifischen Anwendungsfall zuschneiden und die Komplexität und die Hostingkosten reduzieren.
Dieser Beitrag beschreibt die Entwicklung einer Zeitreihendatenbank, bei der auf schicke Cloud-Lösungen zugunsten von bekannten und bewährten Tools verzichtet wird: PostgreSQL und Rust (diesel + actix) - lesen Sie mehr über die Gründe unten.
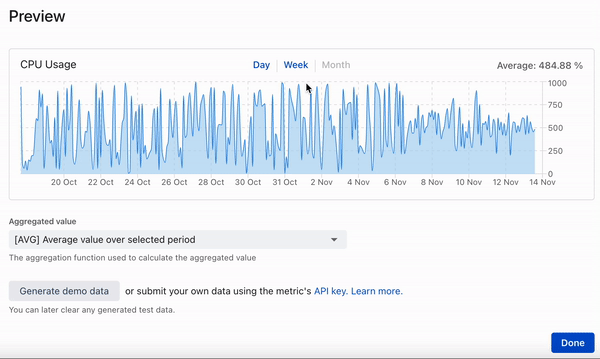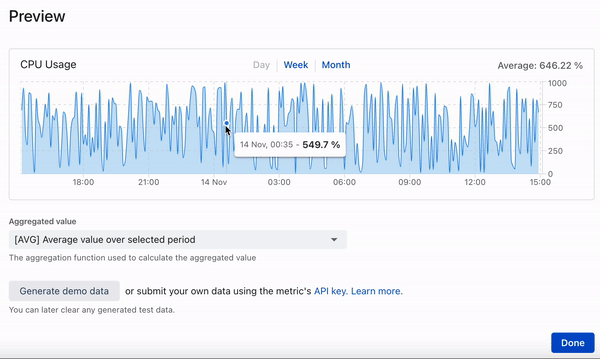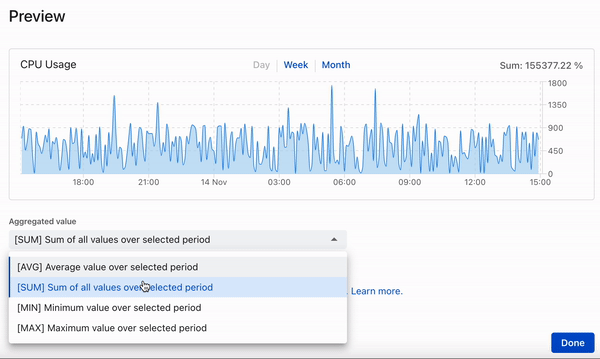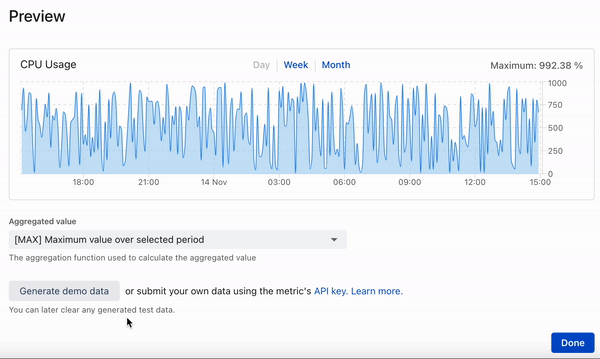
Dieser Beitrag beschreibt die Entwicklung einer Zeitreihendatenbank, bei der auf schicke Cloud-Lösungen zugunsten von bekannten und bewährten Tools verzichtet wird: PostgreSQL und Rust (diesel + actix) - lesen Sie mehr über die Gründe unten.
Warum Rust verwenden?

Rust hat im Laufe der Jahre an Popularität gewonnen und wird in vielen verschiedenen Bereichen der Programmierung verwendet, wie zum Beispiel in der Spieleentwicklung, Mikrocontroller-Anwendungen und sogar in der Webentwicklung.
Ein wesentlicher Unterschied zu anderen Low-Level-Programmiersprachen wie C/C++ ist das Speichermanagement, zu dem Funktionen wie Besitztümerschaften, der Borrow-Checker und Lebensdauern gehören, die Entwicklern helfen, Speicherfehler zu vermeiden. Diese Fehler werden bereits zur Kompilierzeit erkannt. Darüber hinaus benötigt der laufende Prozess keinen Garbage Collector wie in Java oder C#. Eine hohe Leistung bei der Verarbeitung großer Datenmengen und die Unterstützung für nebenläufige Programmierung mit tokio sind ein großer Vorteil für unseren Anwendungsfall, eine Zeitreihendatenbank zu erstellen und auszuführen.
Bei ilert lieben wir auch die Tatsache, dass Rust es uns ermöglicht, Service-Artefakte mit einem extrem kleinen Footprint zu versenden. Die Docker-Images der Services überschreiten in der Regel nicht 20 MB, und der Speicherverbrauch unserer Services (abhängig von der Last) ist super effizient und hält den benötigten RAM oft unter 10 MB. Dies ermöglicht es uns, Container zu skalieren und die Last über mehrere Kubernetes-Cluster hinweg auszugleichen, wobei der Schwerpunkt auf hoher Verfügbarkeit liegt und der Kostenfaktor für das Ausführen so vieler Container ignoriert wird.
Warum PostgreSQL verwenden?

PostgreSQL ist ein Open-Source-objektrelationales Datenbanksystem, das die Verwendung und Erweiterung der SQL-Sprache ermöglicht und viele Funktionen kombiniert, um die komplexesten Datenlasten sicher zu speichern und zu skalieren.
PostgreSQL kommt aus dem MySQL-Hintergrund, eine der nützlichsten Funktionen bei der Erstellung einer Zeitreihendatenbank ist die Fähigkeit, Arrays und mehrdimensionale Arrays zu verwenden, die es uns ermöglichen, mehrere Werte in einem "Zeitcontainer" in einer einzigen Zeile zu speichern und zuzuweisen.
Ingestion Stack, Steuerung des Zeitreihendatenflusses
Das folgende Diagramm veranschaulicht den Ingestion-Prozess:
Wir verwenden AWS Lambda, um eingehende Zeitreihendaten zu validieren und zu authentifizieren und sie an AWS SNS (Simple Notification Service) weiterzuleiten, das dann an AWS SQS (Simple Queue Service) weitergeleitet wird. Unser Rust-Service, der auf AWS EKS (Elastic Kubernetes Service) bereitgestellt wird, empfängt die Nachrichten aus der Warteschlange und verarbeitet sie, um sie in unserer PostgreSQL-Datenbank zu speichern.
Der gesamte serverlose Ingestion-Warteschlangen-Stack stellt sicher, dass wir leicht skalieren können und hilft uns, den eingehenden Fluss von Zeitreihendaten zu kontrollieren. Wir können den Rust-Dienst und die Postgres-Instanzen hinter der Warteschlange individuell skalieren, um den Eingangsdruck mit dem Ausgangsverbrauch in Einklang zu bringen.
Eine vereinfachte Version einer solchen Nachricht sieht wie folgt aus:
Speicherung und Partitionierung von Zeitreihendaten
Ausgehend von der oben beschriebenen Meldung könnte man einfach beschließen, jeden Reihenwert in einer Zeile zu speichern.
Bei einer Skalierung auf Hunderttausende von Metriken müssen wir jedoch mit Milliarden von Zeilen umgehen. Die Speicherung eines einzigen Wertes pro Sekunde und Monat für eine einzige Kennzahl führt bereits zu 2 678 400 Zeilen.
Durch die Einführung eines "Containers", der sich über ein bestimmtes Zeitfenster, z. B. 1 Stunde, erstreckt, könnten wir die Anzahl der Zeilen bereits um den Faktor 60 reduzieren und kämen auf nur 44 640 Zeilen:
Wie können wir dies erreichen? Wir müssen zwei Dinge tun:
- Wir verwandeln unsere Reihenspalte in ein mehrdimensionales Array series double precision -> series double precision[][]
wobei der Zeitstempel auf der linken Seite und der Wert auf der rechten Seite gespeichert wird. - Abschneiden des Zeitstempels der eingehenden Reihe auf der Grundlage der Größe unseres Containers für eingehende Reihendaten, um die richtige Stelle zum Anhängen des Arrays zu finden
Aber es gibt noch mehr.
Was ist, wenn wir für unseren Anwendungsfall keine Sekunden- oder gar Millisekundengenauigkeit benötigen?
Stellen Sie sich ein Diagramm vor, das einen Monat lang Datenpunkte in einer Breite von einigen hundert Pixeln auf einem mobilen Gerät anzeigt. Auf keinen Fall könnten wir 44640, geschweige denn 2678400 Datenpunkte darin unterbringen.
Wir haben festgestellt, dass der Sweet Spot für ein solches Diagramm irgendwo zwischen 250 und 500 Datenpunkten liegt. Schließlich wollten wir flexibel sein und haben die Genauigkeit (Trunkierungsstufe 1 und 2) dynamisch gestaltet, so dass wir sie jederzeit an die verschiedenen Anwendungsfälle anpassen können.
Wir haben uns jedoch für 30 Sekunden als Standardwert entschieden, was bedeutet, dass wir 2 Datenpunkte pro Minute und Metrik speichern.
Bei der zweiten Gruppierung wird der Zeitstempel der Reihe nicht nur auf den Container (row.ts), z. B. 1 Stunde, sondern auch ein zweites Mal auf den Index des linken Arrays (row.series[i][]), z. B. 30 Sekunden, abgeschnitten. Damit ergibt sich eine maximale Größe für die einzelnen Arrays, mit der wir arbeiten können: 3600 / 30 = 120.
Vorbehalte
Dieser Entwurf hat jedoch seine Tücken: Wir können nicht mehr einfach eine INSERT INTO time_series-Anweisung ausführen, um Daten zu speichern. Wir müssen wissen, ob wir einen neuen Container (Zeile) erstellen müssen, wenn dieser noch nicht existiert.
Wenn man außerdem beschließt, dass es möglich sein soll, vorhandene Zeitpunkte zu überschreiben, was wir ermöglichen wollen, muss man auch wissen, ob der Datenpunkt dem Array hinzugefügt oder ein bereits vorhandener Eintrag überschrieben werden soll - außerdem garantiert das Array keine Ordnung mehr, was wir bei der Abfrage der Daten berücksichtigen müssen.
Um zu verstehen, was für jeden Zeitreihenpunkt getan werden muss, öffnen wir eine Transaktion und führen eine Abfrage ähnlich der folgenden aus:
Hinweis: FOR UPDATE sperrt die Zeile, falls sie existiert
e nach Ergebnis werden wir wissen, ob wir es tun müssen:
- Erstellen Sie eine neue Zeile für diese Stunde (abgeschnitten 3600) container insert into timeseries values (1663160400, 1, '{{1663160400, 0.02}}')
- Anhängen eines neuen Zeitreihenwerts an das bestehende Zeilen-Array update timeseries set series = series || '{1663160400, 0.02}}
- Überschreiben eines bestehenden Index im Array der Zeile mit einem neuen Wert update timeseries set series[1663160400][2] = 0.02
Abrufen und Aggregieren von Zeitreihendaten
Bevor wir uns mit dem spezifischen SQL zur Abfrage von Zeitreihendaten befassen, wollen wir einen Blick auf die REST-Schnittstelle werfen, die von anderen Diensten für den Zugriff auf Zeitreihendaten verwendet wird.
- "from" und "until" sind ziemlich selbsterklärend. Wir müssen einen Bereich angeben, für den wir die Daten abrufen möchten, z.B. die letzten 28 Tage.
- Die Aggregation wird immer angewendet, wenn Daten abgefragt werden, und der Standardwert ist Durchschnitt.
- "interval-sec" ist immer erforderlich und beschreibt die Fenstergröße für die Aggregation.
Hier passiert das eigentliche Magische für unsere Abfrage. Wir haben bereits oben festgestellt, dass ein optimaler Bereich für die Anzeige eines Diagramms irgendwo zwischen 250 und 500 Datenpunkten liegt, und da wir etwa alle 30 Sekunden einen Zeitpunkt speichern, haben wir immer noch viel mehr Punkte als das (80640) in einer Monatsansicht. Mit dieser Fenstergröße in Sekunden können wir PostgreSQL weitere Aggregationen unserer Zeitreihendaten auf die gewünschte Anzahl von Zeitpunkten für unser Diagramm vornehmen lassen.
Unsere Abfrage arbeitet dann in etwa vier Teilen:
- Die stündlichen Behälter (Zeilen), die zum bereitgestellten Zeitbereich "from" und "until" passen, abfragen (Abschneiden für Eingabe ist hier erforderlich, um genau zu arbeiten)
- PostgreSQL unnest() verwenden, um unsere Array-Elemente in Zeilenergebnisse umzuwandeln
- Gruppieren nach abgeschnittenem "interval-sec", während Aggregationen durchgeführt werden
- Die Reihenfolge der Zeitstempel sicherstellen
Ein vereinfachtes Beispiel für eine Abfrage, die für unseren obigen HTTP-Request erstellt würde, würde etwa so aussehen:
Hinweis: Basierend auf den "interval-sec"-Werten für "date_trunc()" und "extract()" werden dynamische, aber deterministische Gruppierungsfenster (im SQL-Statement als "slot" bezeichnet) erstellt. Die resultierenden Zeilen enthalten keine Zeitstempel, sondern relative Werte zu diesen Slots. Der Rust-Code wird dann die Zeitstempel basierend auf den Ergebnissen und Eingabeparametern neu erstellen.
Ein Beispiel für das Ergebnis der obigen Abfrage würde nach der Verarbeitung aller Ergebniszeilen in einer JSON-Antwort etwa so aussehen:
Ausblick
In der Softwareentwicklung sind neue Frameworks, Bibliotheken oder in diesem Fall Datenbanken nicht immer erforderlich oder besser, wenn Anwendungsfälle ordnungsgemäß identifiziert und verstanden werden. Oft können Lösungen auf der vorhandenen Stack-Basis einfacher gehalten und implementiert werden, ohne die Komplexität des gesamten Stacks zu erhöhen.
Es gibt sogar weitere Vorteile, wenn man eine Lösung wie diese in ein bekanntes Konzept integriert, da die anderen Teile des bestehenden Ökosystems bereits mit ihnen integriert sind. In unserem Fall betrifft dies:
- Leistungs- und Einblicksmetriken
- Geschäftsmetriken
- Protokollierung
- Skalierung (k8s)
- Compliance & DSGVO
- Überwachung
- Benachrichtigung
- Build-Pipelines (CI & CD)
Wenn Sie Metriken und die Zeitreihen-API in Aktion ausprobieren möchten, spielen Sie gerne damit in Ihrem eigenen ilert-Konto herum: Es ist kostenlos.
Wenn Sie mehr darüber erfahren möchten, wie wir bei ilert Mikroservices, Zeitreihendatenbanken oder Alarmierungsplattformen in Rust erstellen, kontaktieren Sie uns.

.avif)







