ilert ist die Incident-Management-Lösung, die von Grund auf als Single-Application konzipiert wurde und den gesamten Lebenszyklus der Reaktion auf Vorfälle abdeckt.
Die Funktionen, die Sie für den Betrieb von Always-On-Services benötigen
Jede Funktion in ilert wurde entwickelt, um Ihnen zu helfen, schneller auf Vorfälle zu reagieren und die Verfügbarkeit zu erhöhen.
Nutzen Sie das Potenzial generativer AI
Verbessern Sie die Kommunikation bei Vorfällen und optimieren Sie die Erstellung von Post Mortems mit ilert AI. ilert AI unterstützt Ihr Unternehmen dabei, schneller auf Vorfälle zu reagieren.
ilert stellt mithilfe unserer vorgefertigten Integrationen oder per E-Mail eine nahtlose Verbindung zu Ihren Tools her. Ilert lässt sich in Überwachungs-, Ticketing-, Chat- und Kollaborationstools integrieren.
So erreichen führende Unternehmen mit ilert eine Uptime von 99,9 %
Unternehmen weltweit vertrauen auf ilert, um ihr Incident-Management zu optimieren, die Zuverlässigkeit zu steigern und Ausfallzeiten zu minimieren. Lesen Sie, was unsere Kunden über ihre Erfahrungen mit unserer Plattform sagen.
Eine Incident-Response-Plattform hilft Unternehmen dabei, IT-Störungen schnell und effizient zu behandeln, zu verfolgen und zu lösen. Mit der richtigen Plattform können IT-Teams Ausfallzeiten minimieren, die Auswirkungen von Störungen verringern und insgesamt ihre Reaktionszeiten verbessern.
In diesem Artikel stellen wir die fünf besten Incident-Response-Plattformen für 2025 vor – und helfen Ihnen dabei, die passende Lösung für Ihre Anforderungen zu finden.
Diese Liste ist nicht 100 % objektiv – schließlich bieten wir selbst eine vollständige End-to-End-Plattform für Incident-Management an. Dennoch haben wir uns bemüht, die Bewertung so fair wie möglich zu gestalten. Alle aufgeführten Plattformen sind bewährt, robust und in der Lage, sämtliche operativen Anforderungen zu erfüllen. Wir zeigen außerdem Gemeinsamkeiten und Unterschiede auf, um Ihnen die Orientierung zu erleichtern – selbst wenn Sie sich dann doch nicht für uns entscheiden.
Die wichtigsten Punkte
Die Wahl des richtigen Incident-Management-Tools ist entscheidend für eine effektive Reaktion auf IT-Störungen – insbesondere für Unternehmen, die sich mit EU-Regularien und jüngsten Veränderungen wie dem EOL von OpsGenie auseinandersetzen müssen.
Zu den wichtigsten Funktionen gehören Multi-Channel-Alarmierung, automatisierte Workflows, anpassbare Eskalationsrichtlinien und leistungsstarke Integrationen in bestehende Systeme.
Die führenden Plattformen bieten fortschrittliche Funktionen, die auf unterschiedliche organisatorische Anforderungen zugeschnitten sind. Sie unterscheiden sich jedoch stark in Bezug auf Kosten und Eignung für verschiedene Teamgrößen.
Bei der Bewertung von Plattformen im Jahr 2025 stechen einige Kernfunktionen besonders hervor.
Beginnen wir mit der Alarmierung: Eine moderne Plattform muss Multi-Channel-Alerting unterstützen – also Sprachanrufe, SMS, Push-Nachrichten, E-Mail sowie Chat-Tools wie Slack oder Microsoft Teams – und eine vollständig interaktive Nutzererfahrung bieten, ohne dass sich Nutzer einloggen oder die App wechseln müssen.
Die Reaktionszeit ist entscheidend – und je reibungsloser der erste Schritt verläuft, desto eher lässt sich ein größerer Ausfall vermeiden. Fortgeschrittene Funktionen wie Deduplizierung von Alarmierungen, intelligente Gruppierung, Vermeidung von Alarmflut durch Filterregeln und wiederverwendbare Templates helfen dabei, Überlastung und Abstumpfung (Alert Fatigue) zu reduzieren, indem nur relevante und priorisierte Meldungen durchkommen.
Ein weiterer wichtiger Aspekt ist die Verwaltung von Dienstbereitschaften. Plattformen sollten automatisierte Dienstpläne mit Unterstützung für Rotationen, Ausnahmen und Übergaben bieten – sowie vollständig anpassbare Eskalationsrichtlinien. So wird sichergestellt, dass die richtige Person je nach Priorität, Tageszeit oder anderen Bedingungen informiert wird. Die Benutzeroberfläche sollte für alle Teammitglieder einfach zu bedienen sein.
Integrationsfähigkeit ist entscheidend, um den Incident-Response-Prozess nahtlos in das vorhandene Tool-Set einzubetten. Führende Plattformen bieten native Integrationen mit Monitoring- und Observability-Tools (z. B. Prometheus, Datadog, PRTG), Log-Aggregatoren (z. B. Loki), ITSM-Tools (z. B. ServiceNow, Jira Service Management) und CI/CD-Systemen (z. B. GitHub, GitLab).
Auch Statusseiten sind ein wertvolles Feature: Sie ermöglichen bei Störungen eine transparente Kommunikation mit Nutzern und Beteiligten, reduzieren die Anzahl an Supportanfragen und stärken das Vertrauen der Nutzer in das Unternehmen.
Nicht zuletzt ist die Nachbearbeitung von Störungen ein Muss. Plattformen sollten die Erstellung von Postmortems automatisieren – durch die Erfassung von Timelines, Chatverläufen, Alarmierungen und der Schritte, die zur Lösung der Störung unternommen wurden. Das reduziert nicht nur administrativen Aufwand, sondern ermöglicht auch eine effektive Ursachenanalyse und eine kontinuierliche Verbesserung der Performance.
Kurz gesagt: Eine moderne Incident-Management-Plattform sollte als zentrales Steuerungselement fungieren – perfekt in das Tool-Set integriert, nach Möglichkeit automatisiert und als Hilfsmittel dafür, dass die Beteiligten sich auf die wichtigsten Entscheidungen konzentrieren können.
ilert: die All-in-One-Lösung für Incident-Management aus Europa
ilert ist eine moderne, in Europa entwickelte Plattform für Incident-Management, die End-to-End-Workflows bietet – mit leistungsstarken Alarmierungstools, Planung von Dienstbereitschaften, Automatisierung und Statuskommunikation in einer einzigen Lösung.
Mit einer 100 % interaktiven Multi-Channel-Alarmierung (SMS, Anruf, Push, E-Mail, Slack, MS Teams), ermöglicht ilert eine schnelle Reaktion und ein nahtloses On-Call-Erlebnis.
Die intelligente Behandlung von Alarmierungen beinhaltet KI-gestützte Deduplizierung, Gruppierung, dynamisches Routing, flexible Templates und über 100 Integrationen mit Tools wie Prometheus, Zabbix, Grafana, Datadog und AWS CloudWatch. Die intuitive Bereitschaftsplanung unterstützt Rotationen, Ausnahmen und Eskalationsrichtlinien – alles konfigurierbar per Web-UI oder Mobile App.
Das erweiterte Call-Routing von ilert fungiert als smarte Hotline mit mehrsprachigem IVR, KI-Sprachagent, PIN-Schutz, Blocklist-Handling und Voicemail-Fallback – ideal für Operations-Teams und MSPs.
Integrierte Statusseiten (öffentlich, privat oder zielgruppenspezifisch) ermöglichen eine transparente Echtzeitkommunikation bei Störungen und entlasten den Support. Im Gegensatz zu Standalone-Lösungen sind sie nativ integriert – für maximale Automatisierung und Konsistenz.
Als deutsches Unternehmen ist ilert DSGVO-konform und bietet EU-Datenresidenz – eine sichere Wahl für datenschutzsensible Organisationen. Besonders nach dem EOL von Opsgenie ist ilert eine moderne, agile und kundennahe Alternative zu PagerDuty und Opsgenie.
Zu den Kunden gehören u. a. IKEA, Lufthansa Systems, Adesso und NTT Data.
ilert unterstützt vielfältige Anwendungsfälle – von DevOps und SecOps bis hin zu Industrieanwendungen – und punktet vor allem bei MSPs und IT-Dienstleistern mit Funktionen wie Multi-Tenant-Support, benutzerdefiniertem Routing und SLA-zentriertem Design.
PagerDuty: Der Veteran im Incident-Management
PagerDuty gilt seit Langem als Pionier im Bereich Incident-Management. Seit der Gründung im Jahr 2009 hat sich die Plattform zu einer umfassenden Lösung entwickelt – primär für DevOps- und SRE-Teams in großen, komplexen Umgebungen. Sie bietet einen ausgereiften Funktionsumfang, darunter Multi-Channel-Alarmierung, Planung von Bereitschaftsdiensten, Eskalationsrichtlinien und Echtzeit-Tracking von Störungen.
Eine der großen Stärken von PagerDuty ist das umfangreiche Integrations-Ökosystem: die Lösung unterstützt eine große Anzahl Tools wie Datadog, New Relic, AWS CloudWatch, Splunk und viele mehr. Zudem nutzt PagerDuty Event Intelligence: Mit Hilfe von Machine Learning werden irrelevante Alarmierungen unterdrückt, zusammengehörige Ereignisse korreliert und Störungen priorisiert – was Teams hilft, sich auf das Wesentliche zu konzentrieren.
Für große Unternehmen bietet PagerDuty zusätzliche Features wie Runbook Automation, Service Graphs und Business Impact Metrics, um Abhängigkeiten zu verwalten, Auswirkungen besser einzuschätzen und technische Vorgänge mit geschäftlichen Zielen abzugleichen.
Allerdings hat dieser große Funktionsumfang auch seinen Preis: Viele Teams – insbesondere in mittelgroßen Unternehmen oder mit einfacheren Anforderungen – empfinden PagerDuty als überladen und komplex, mit einer steilen Lernkurve und einem Preismodell, das bei wachsendem Team schnell teuer wird.
Kurz: PagerDuty ist und bleibt eine leistungsfähige und bewährte Plattform – besonders für große Unternehmen mit hohem Automatisierungs- und Integrationsbedarf. Doch für Teams, die eine agilere, kosteneffizientere und datenschutzkonforme Lösung suchen – vor allem in Europa – gibt es inzwischen moderne Alternativen, die besser zu aktuellen Anforderungen passen.
xMatters ist ein etablierter Anbieter im Bereich Incident-Management mit einem starken Fokus auf Workflow-Automatisierung und ereignisgesteuerte Orchestrierung. Die Plattform richtet sich an DevOps-, ITOps- und Business-Continuity-Teams und ermöglicht es, individuelle Workflows zu erstellen, die Monitoring-Systeme, Benachrichtigungskanäle, Ticketing-Tools und mehr miteinander verbinden – alles über eine Low-Code-Oberfläche.
Zu den Incident-Response-Funktionen von xMatters gehören Multi-Channel-Alarmierung, Bereitschaftsplanung, Eskalationen und automatisierte Reaktionen. Das Besondere an xMatters ist die Möglichkeit, Workflows zu definieren, die bei bestimmten Bedingungen automatisch ausgelöst werden.
Allerdings kann xMatters den Eindruck vermitteln, dass es sich mehr auf die Prozessautomatisierung als auf die praktische, anwenderfreundliche Behebung von Störungen konzentriert.
IT-Teams, die eine intuitive UI und eine enge Verzahnung mit modernen DevOps-Prozessen suchen, könnten es als weniger direkt empfinden als alternative Lösungen wie ilert oder PagerDuty. Auch die Benutzeroberfläche und die Einrichtung gelten als komplex – insbesondere für kleinere Teams ohne dedizierte Experten für das Setup von Tools.
Für Unternehmen mit starkem Fokus auf ITSM und Prozessautomatisierung ist xMatters dennoch eine leistungsstarke und individuell anpassbare Lösung – für reine Incident-Response jedoch manchmal überdimensioniert.
Grafana IRM: Integriertes Incident-Management für das Grafana-Ökosystem
Grafana IRM (Incident Response & Management) ist die neue integrierte Lösung von Grafana Labs, die Grafana OnCall und Grafana Incident zu einer einzigen cloudbasierten Plattform vereint. Sie wurde speziell für IT-Teams entwickelt, die bereits auf Grafana Cloud für Observability setzen. Die Plattform deckt den gesamten Lebenszyklus einer Störung ab – von der Erkennung bis zur Behebung.
Ein wesentlicher Vorteil liegt in der nahtlosen Integration mit Tools wie Loki, Tempo und Prometheus. IT-Teams können Störungen direkt über ihre Dashboards erstellen, verfolgen und beheben – ohne zwischen Tools wechseln zu müssen. Die Plattform bietet integrierte Dienstplan-Verwaltung, Eskalationen, Incident-Tracking und anpassbare Workflows zur Steuerung von Benachrichtigungen, Eskalationen und Postmortems. Alle Beteiligten werden dabei stets über native Benachrichtigungen informiert.
Für Teams, die bereits mit Grafana Cloud arbeiten, bietet IRM Komfort und Geschwindigkeit. Es reduziert die Anzahl der Tools, verringert die Komplexität der Einbindung und sorgt dafür, dass die Reaktion auf Störungen eng mit der Überwachung und Protokollierung verknüpft bleibt. Der Einstieg ist unkompliziert, das Setup schnell erledigt – ideal für schlanke Incident-Prozesse.
Allerdings ist die Plattform stark an die Grafana Cloud gebunden. Wer hybride oder nicht-Grafana-Stacks nutzt, stößt schnell an Grenzen. Auch fortgeschrittene Features wie KI-gestützte Deduplizierung, Sprach-Routing oder Mandantenfähigkeit fehlen – Funktionen, die dedizierte Plattformen wie ilert oder PagerDuty besser abdecken.
Kurzum: Eine starke Lösung für Grafana-Nutzer – aber eher Ergänzung als Ersatz für komplexe oder heterogene Umgebungen.
OpsGenie: Die Lösung für Nutzer von Jira-Service-Management
Opsgenie war lange Zeit eine beliebte Lösung für Alarmierung und Dienstbereitschaft – insbesondere im Atlassian-Kontext. Mit einer übersichtlichen Benutzeroberfläche, zuverlässiger Alarmierungs-Logik und enger Integration mit Jira und Confluence war Opsgenie ideal für viele DevOps- und IT-Teams, die bereits Atlassian-Produkte nutzen.
Die Plattform bot klassische Funktionen wie On-Call-Planung, Multi-Channel-Alarmierung, Eskalationen und Integrationen mit Monitoring-Tools wie Datadog und Prometheus. Durch anpassbare Alarmierungen und Störungs-Timelines ließ sich der gesamte Incident-Response-Prozess gut nachvollziehen – inklusive Slack-Unterstützung für Team-Kommunikation.
Daher suchen viele Unternehmen nach gleich zuverlässigen Alternativen – aber mit besserem Support, einer klaren Roadmap und höherer Flexibilität. Plattformen wie ilert bieten nicht nur einfache Migrationspfade, sondern auch DSGVO-Konformität, bessere Automatisierung und modernere On-Call-Funktionen.
Für Unternehmen, die ohnehin auf JSM setzen, bleibt Opsgenie (bzw. sein Nachfolger) dennoch eine sinnvolle Option – allerdings zunehmend als Bestandteil einer größeren ITSM-Suite.
Fazit
Die Wahl der richtigen Incident-Response-Plattform ist entscheidend für eine zuverlässige Leistung und schnelle Reaktion bei Störungen. Jede der in diesem Beitrag vorgestellten Plattformen hat ihre individuellen Stärken – passend für unterschiedliche Teamgrößen, Branchen und Anforderungen.
Ob Sie nun eine hochintegrierte Enterprise-Lösung suchen oder eine agile, datenschutzfreundliche Alternative – mit der richtigen Plattform stellen Sie die Weichen für ein effizientes und modernes Incident-Management.
Eine Postmortem-Vorlage ist eine strukturierte Hilfe zur Dokumentation von Incidents, zur Analyse ihrer Ursachen und zur Ableitung von Maßnahmen zur Prävention. In diesem Artikel stellen wir die Schlüsselelemente eines effektiven Postmortems vor und zeigen, wie ilert diesen Prozess optimiert und ihre Incident Response effizienter gestaltet. Zusätzlich bieten wir eine herunterladbare Postmortem-Vorlage an – ideal, wenn Sie noch keine Incident Management Plattform in Ihrem Unternehmen einsetzen.
Wichtige Erkenntnisse
Postmortem-Vorlagen verwandeln Incidents in wertvolle Lernchancen, indem sie Schwachstellen aufdecken und künftige Reaktionen verbessern.
Postmortems dienen sowohl der teaminternen Verbesserung als auch der transparenten Kommunikation mit Stakeholdern.
Zentrale Bestandteile eines guten Postmortems sind Incident-Timeline, Auswirkungen, Gegenmaßnahmen und Root Cause Analysis.
Warum Postmortems im Incident Management unverzichtbar sind
Postmortems sind weit mehr als nur Dokumente – sie sind Blaupausen für kontinuierliche Verbesserung. Die strukturierte Dokumentation hilft dabei, Systemschwachstellen zu erkennen und künftige Incidents effizienter zu bewältigen. Neben der akuten Problemlösung schaffen Postmortems eine Wissensbasis für zukünftige Vorfälle.
Stellt euch die typische Incident-Situation vor: Systeme fallen aus, User sind betroffen, und die Zeit läuft. Wenn sich der Staub gelegt hat, hilft euch eine gut strukturierte Postmortem-Vorlage dabei, das Chaos zu analysieren. Schritt für Schritt zeigt sie auf, was passiert ist, warum es passiert ist und wie man solche Vorfälle künftig verhindern kann. So wird aus einem negativen Ereignis eine wertvolle Lernerfahrung.
Ein standardisierter Postmortem-Prozess stellt außerdem sicher, dass jedes Incident gründlich analysiert wird. So lassen sich Muster und wiederkehrende Probleme erkennen – ein wichtiger Hebel für proaktives Incident Management.
Wichtige Elemente einer effektiven Postmortem-Vorlage
Eine gute Postmortem-Vorlage beginnt mit einem klaren Titel und einer kurzen Einleitung, die den Incident zusammenfasst. So erhält der Leser sofort den nötigen Kontext.
Darauf folgt die Incident-Timeline – eine chronologische Darstellung der Ereignisse inklusive Zeitstempel. Diese hilft, den Ablauf und auslösende Faktoren nachzuvollziehen.
Der Abschnitt "Auswirkungen und Schadensbegrenzung" beschreibt die Auswirkungen des Incidents auf die User und dokumentiert die umgehend ergriffenen Maßnahmen zur Schadensbegrenzung. Er verdeutlicht die reale Tragweite des Vorfalls und wie effektiv das Team darauf reagiert hat.
Das Herzstück jedes Postmortems sind die Ursachenanalyse und die gewonnenen Erkenntnisse. Durch die Identifikation der eigentlichen Ursache können präventive Maßnahmen eingeleitet werden. Die “Lessons Learned” zeigen, was gut funktioniert hat – und was nicht – und stärken die Lernkultur im Team.
Ein einheitliches Format erleichtert nicht nur die Analyse, sondern auch die langfristige Verbesserung des Incident Managements. Regelmäßige Aktualisierungen der Vorlage auf Basis von Feedback erhöhen ihre Wirksamkeit. Eine gute Postmortem-Vorlage ist also kein statisches Dokument, sondern ein dynamisches Tool für kontinuierliches Lernen.
Die integrierte Postmortem-Funktion von ilert
ilert nimmt euch den Aufwand der Postmortem-Erstellung ab. Die Plattform sammelt automatisch Daten aus incident-relevanten Kommunikationskanälen und Status-Updates. Das spart wertvolle Zeit und Ressourcen direkt nach einem Vorfall.
Dank Integration mit Slack und Microsoft Teams kann ilert automatisch Alerts und relevante Nachrichten aus verknüpften Channels zusammenstellen. Ihr müsst also keine Chatverläufe manuell durchforsten.
Nach Erstellung erhält das Dokument den Status „erstellt“. Es kann als Markdown oder Rohtext bearbeitet werden – ideal zur Feinabstimmung vor dem Teilen mit Stakeholdern.
Postmortems lassen sich direkt mit Incidents verknüpfen und auf entsprechenden Statusseiten veröffentlichen. So bleibt das gesamte Team auf dem gleichen Stand. ilert verschlankt den gesamten Prozess, damit ihr euch auf Ursachenanalyse und kontinuierliche Verbesserung konzentrieren könnt.
Beispiel-Incident und Postmortem-Erstellung mit ilert
Stellen wir uns das folgende Szenario vor, um Ihnen ilert in Aktion zu zeigen und die Struktur des Postmortem-Prozesses besser zu verstehen.
Szenario eines Vorfalls
Company XY ist ein Webhosting-Anbieter und nutzt einen Cloud Provider zur Auslieferung der Websites seiner Kunden. Bei einem Ausfall des Providers werden sie automatisch benachrichtigt.
Am späten Nachmittag lösen mehrere Alerts in ilert aus – einige Websites von Kunden sind nicht erreichbar. Etwa die Hälfte der Kunden ist betroffen. Der Responder eskaliert das Problem und erstellt einen Incident. Gregory setzt den Status auf „Investigating“, was sofort auf der Status Page erscheint. Nach der Identifikation der Ursache wird der Status auf „Identified“ gesetzt. Francesca übernimmt, holt Infos vom Provider ein und stellt auf „Monitoring“. Nach 1,5 Stunden wird der Incident behoben, der Status wechselt auf „Resolved“.
(Falls euch die Unterscheidung zwischen Alerts und Incidents unklar ist: Alerts sind technische Signale aus Monitoring-Tools, während Incidents tatsächliche Störungen mit Auswirkungen auf User darstellen und kommuniziert werden müssen.)
Das Team erhält Alarme und kommuniziert über die Incident-Management-Plattform von ilert.
Ein Incident wird in ilert erstellt.
Der Incident wird behoben.
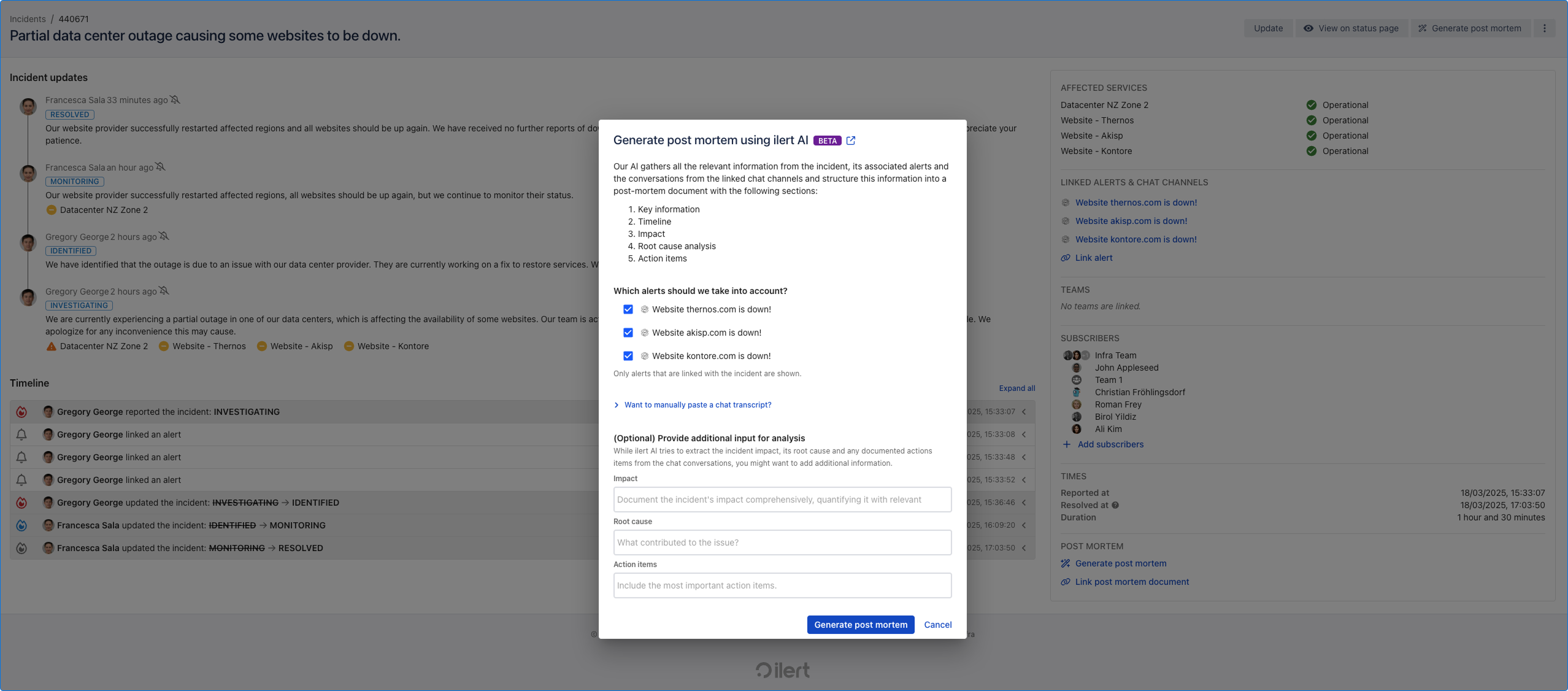
Automatische Postmortem-Erstellung mit ilert KI.
Eine Vorschau des mit ilert KI erstellten Postmortem-Dokuments.
Automatisierte Postmortem-Erstellung
Nach Behebung des Vorfalls erstellt das Engineering-Team einen Postmortem-Report. ilert analysiert alle verfügbaren Daten – Alerts, Logs, Nachrichten, Status Updates – und erstellt ein klares, strukturiertes Dokument.
Alle Postmortems werden in ilert gespeichert, können aber auch als Textdatei heruntergeladen werden.
# [00000 Partial data center outage causing some websites to be down.](https://test.ilert.com/incidents/view?id=000)
Generated by Francesca Sala on 18.03.2025 17:40.
All timestamps are local to Europe/Berlin.
# Post-Mortem Document
## Incident Timeline
### March 18, 2025
- **14:26:24.109Z**: Received event from alert source indicating website thernos.com is down.
- **14:26:25.426Z**: Francesca Sala notified via email.
- **14:26:25.437Z**: Gregory George notified via email.
- **14:26:24.129Z**: Assigned to Gregory George.
- **14:27:06.664Z**: Accepted by Gregory George.
- **14:33:52.317Z**: Gregory George linked incident 'Partial data center outage causing some websites to be down' to this alert.
- **14:36:46.682Z**: Gregory George changed linked incident status to Identified.
- **14:59:00.145Z**: Gregory George added a comment regarding an email from Thernos asking for an estimate on website restoration.
- **15:00:28.502Z**: Francesca Sala added a comment indicating the provider is restarting affected regions.
- **15:09:21.785Z**: Francesca Sala changed linked incident status to Monitoring.
- **16:03:51.741Z**: Francesca Sala changed linked incident status to Resolved.
- **16:06:36.737Z**: Francesca Sala added a comment indicating the incident is resolved and the website is online again.
- **16:06:36.737Z**: Incident resolved by Francesca Sala.
### March 18, 2025 (Additional Alerts)
- **14:26:30.692Z**: Received event from alert source indicating website akisp.com is down.
- **14:26:31.884Z**: Francesca Sala notified via email.
- **14:26:31.887Z**: Gregory George notified via email.
- **14:26:30.705Z**: Assigned to Gregory George.
- **14:27:06.640Z**: Accepted by Gregory George.
- **14:33:48.699Z**: Gregory George linked incident 'Partial data center outage causing some websites to be down' to this alert.
- **14:36:46.699Z**: Gregory George changed linked incident status to Identified.
- **15:09:21.813Z**: Francesca Sala changed linked incident status to Monitoring.
- **16:03:51.770Z**: Francesca Sala changed linked incident status to Resolved.
- **16:06:36.524Z**: Francesca Sala added a comment indicating the incident is resolved and the website is online again.
- **16:06:36.524Z**: Incident resolved by Francesca Sala.
### March 18, 2025 (Additional Alerts)
- **14:26:36.713Z**: Received event from alert source indicating website kontore.com is down.
- **14:26:37.916Z**: Gregory George notified via email.
- **14:26:37.923Z**: Francesca Sala notified via email.
- **14:26:36.737Z**: Assigned to Gregory George.
- **14:27:06.602Z**: Accepted by Gregory George.
- **14:33:08.523Z**: Gregory George linked incident 'Partial data center outage causing some websites to be down' to this alert.
- **14:36:46.716Z**: Gregory George changed linked incident status to Identified.
- **15:09:21.837Z**: Francesca Sala changed linked incident status to Monitoring.
- **16:03:51.802Z**: Francesca Sala changed linked incident status to Resolved.
- **16:06:36.209Z**: Francesca Sala added a comment indicating the incident is resolved and the website is online again.
- **16:06:36.209Z**: Incident resolved by Francesca Sala.
## Impact
The incident caused a partial outage in one of our data centers, affecting the availability of several customer websites, including Thernos, Akisp, and Kontore. Approximately half of our hosted sites were down, leading to customer inquiries and potential business disruptions. The affected websites experienced degraded performance and were unreachable for a period of time, causing inconvenience to users and potentially impacting business operations for the affected customers.
## Root Cause Analysis
The root cause of the incident was identified as an issue with our data center provider. The provider experienced an outage in one of their data centers, which led to the unavailability of several hosted websites. The provider worked on resolving the issue by restarting the affected regions, which eventually restored the services.
## Action Items
1. **Monitoring Provider Status**: Francesca Sala will continue to monitor the cloud provider's status page for updates during incidents.
2. **Customer Communication**: Gregory George will draft and update the status page to keep customers informed during incidents.
3. **Incident Documentation**: Francesca Sala will create and share a post-mortem document after the incident is resolved.
This post-mortem document provides a detailed account of the incident, its impact, root cause, and the actions taken to prevent recurrence.
Verwenden Sie ilert oder laden Sie eine Postmortem-Vorlage herunter und füllen Sie sie manuell aus
Basierend auf dem oben beschriebenen Beispiel stellen wir eine Google Docs-Vorlage zur Verfügung. Falls ihr ilert noch nicht nutzt, könnt ihr damit dennoch einen strukturierten Postmortem-Prozess etablieren. Auch wenn die manuelle Erstellung mehr Zeit kostet, ist sie ein erster wichtiger Schritt für systematisches Lernen nach Incidents.
Ein “blameless” Postmortem konzentriert sich auf gemeinsame Erkenntnisse, nicht auf Schuldzuweisungen. Das schafft ein unterstützendes Umfeld, in dem Teammitglieder offen und ehrlich reflektieren können. Statt „Wer?“ stehen Fragen wie „Was?“ und „Wie?“ im Fokus.
Solche Fragen fördern eine Growth-Mindset-Kultur und machen Verbesserungen möglich. Eine „Keine Schuldzuweisung“-Regel während des Postmortems hält den Fokus auf Prozessen – nicht auf Personen.
ilert AI hilft zusätzlich mit datengestützten, objektiven Bewertungen von Incidents – frei von persönlichen Verzerrungen. So stärkt ihr eine Lernkultur, in der Fehler als Wachstumschancen verstanden werden.
Typische Fehler bei der Postmortem-Erstellung vermeiden
Um den Wert Ihrer Postmortems zu maximieren, sollten Sie diese häufigen Fehler vermeiden – sortiert nach ihrem Einfluss auf langfristiges Lernen und operative Resilienz:
Keine Musteranalyse über mehrere Incidents hinweg
Wenn jeder Incident isoliert betrachtet wird, bleiben wiederkehrende Probleme oft unentdeckt.
Überprüft regelmäßig mehrere Postmortems, um Muster, systemische Schwächen oder Prozesslücken zu erkennen.
Nutzt diese Erkenntnisse für übergreifende Verbesserungen und um ähnliche Incidents in Zukunft zu vermeiden.
Fehlende Nachverfolgung von Maßnahmen
Erkenntnisse sind wertlos ohne Umsetzung. Wenn Postmortem-Maßnahmen nicht abgeschlossen werden, werden sich Vorfälle wahrscheinlich wiederholen.
Weist jeder Maßnahme Verantwortliche und Fälligkeiten zu und verfolgt den Fortschritt konsequent.
Verwendung einer generischen Vorlage
Eine Postmortem-Vorlage nach dem Motto „one-size-fits-all“ lässt oft wichtige, incidentspezifische Details aus.
Passen Sie Ihre Vorlagen an und stellen Sie sicher, dass alle relevanten Informationen enthalten sind – z. B. Zeitachse, Auswirkungen, beitragende Faktoren und Schritte zur Behebung.
Keine “blameless” Kultur
Wenn sich Menschen beschuldigt fühlen, teilen sie ihre Erkenntnisse weniger offen.
Fördert eine Kultur der psychologischen Sicherheit und des Lernens – nicht der Schuldzuweisung.
Unklare oder unkonkrete Rückmeldungen
Feedback ohne Klarheit oder Handlungsbezug führt selten zu echten Verbesserungen.
Ermutigt zu spezifischem, konstruktivem Feedback, das auf konkrete Verbesserungen hinweist.
Schlechte Kommunikation mit Stakeholdern
Wenn Postmortems nicht mit relevanten Stakeholdern geteilt werden, geht wertvolles organisationales Lernen verloren.
Teilen Sie Ihre Erkenntnisse proaktiv mit den betroffenen Teams, der Führungsebene und anderen relevanten Beteiligten, um alle auf dem gleichen Stand zu halten.
Fazit
Postmortem-Vorlagen sind unverzichtbar, um aus Incidents zu lernen. Sie helfen Teams, Schwachstellen im System aufzudecken, Reaktionsstrategien zu verbessern und eine Kultur der kontinuierlichen Verbesserung zu etablieren.
Mit den integrierten Features und der AI-Unterstützung von ilert wird der Postmortem-Prozess deutlich effizienter. Ein strukturierter, blameless Ansatz hilft euch dabei, Incidents als Chancen für Wachstum und nachhaltige Verbesserung zu nutzen.
FAQ
Wofür ist ilert AI bei der Postmortem-Erstellung nützlich?
Sie beschleunigt den letzten Schritt der Incident Response und erlaubt euch, euch aufs Wesentliche zu konzentrieren – die Analyse statt Papierkram.
Was passiert, nachdem ein Incident den Status „Resolved“ erreicht?
Alle relevanten Infos werden gesammelt und dokumentiert, um sicherzustellen, dass alle Beteiligten auf dem gleichen Stand sind. ilert-Nutzer:innen überspringen den manuellen Teil und widmen sich direkt den Diskussionen und Aktions-Items.
Welche Informationen berücksichtigt ilert AI bei der Postmortem-Erstellung?
ilert AI berücksichtigt Incident-Kontext wie Verlauf, Slack/Microsoft Teams-Nachrichten, Abonnenten, betroffene Services, involvierte User und alle zugehörigen Alerts.
Wie können relevante Nachrichten aus Chat-Tools ins Postmortem übernommen werden?
Durch Verknüpfung Ihrer Slack- oder Microsoft Teams-Channels – der ilert Bot scannt sie automatisch. Alternativ könnt ihr Nachrichten manuell einfügen oder kopieren.
In den letzten Wochen habe ich mit mehreren Opsgenie-Kund:innen gesprochen, die nach Atlassians Entscheidung, Opsgenie auslaufen zu lassen und dessen Funktionen in andere Produkte zu integrieren, einen Wechsel zu ilert prüfen. Atlassian bietet Opsgenie-Nutzer:innen „zwei Optionen: den Wechsel zu Jira Service Management für umfassendes Incident Management oder zu Compass für Alerting und On-Call-Management.“ Diese Entscheidung wirft eine grundsätzliche Frage in unserer Branche auf:
Ist Incident Response Management (IRM) eine eigenständige Kategorie – oder nur ein Feature in einer größeren Plattform?
Ich möchte diese Frage aufgreifen und erläutern, warum ich fest davon überzeugt bin, dass IRM eine eigenständige, essenzielle Kategorie bleibt – und nicht einfach ein weiteres Feature ist. Dabei teile ich Erkenntnisse aus Gesprächen mit Kund:innen und zeige, warum ilert konsequent auf eine vendor-neutrale Integrationsstrategie setzt – selbst wenn das bedeutet, eigene Funktionen wie Uptime Monitoring einzustellen.
Was wir aus Opsgenies Ausstieg gelernt haben
Beginnen wir mit den Erkenntnissen aus dem Ende von Opsgenie. Gemeinsam mit PagerDuty war Opsgenie ein Pionier, der das Feld des Incident Response Managements maßgeblich geprägt hat. Sein Aus ist daher bittersüß. Viele Nutzer:innen äußerten Frust darüber, dass die Weiterentwicklung stagnierte, während Atlassian Opsgenies Funktionen nach und nach in Jira Service Management (JSM) integrierte. Einige sind schon vor Atlassians offizieller EOL-Ankündigung zu ilert gewechselt – mit der Begründung, dass Opsgenie sich nicht weiterentwickelte, weil es in JSM aufging.
Genau darin liegt das Problem: Die All-in-One-Lösung JSM enthält zwar Funktionen für Incident Response, kann aber für Teams, die ein schnelles, flexibles Tool für Alerting und On-Call brauchen, umständlich sein. Das Schicksal von Opsgenie zeigt, wie Incident Management eher als Feature eines umfassenderen Toolsets (wie ITSM oder Developer-Portale) verstanden wird – und nicht als eigenständiges Produkt.
Viele Opsgenie-Nutzer:innen, mit denen ich sprach, prüfen zwar die Optionen von Atlassian, sehen sich aber bewusst auch nach spezialisierten IRM-Plattformen um – aus dem Gefühl heraus, dass Incident Response sonst zu kurz kommen würde. Diese Intuition bestätigt eine Erkenntnis, die viele von uns in der Branche teilen.
IRM: Feature oder eigenständige Plattform?
Die Frage ist berechtigt: Könnte Incident Response im Zuge der Weiterentwicklung angrenzender Kategorien (Monitoring, Observability, ITSM) einfach ein Feature unter vielen werden? Viele Monitoring-Tools enthalten mittlerweile Alerting-Funktionen, und IT-Service-Plattformen bieten Incident-Module. Atlassians Umgang mit Opsgenie ist ein prominentes Beispiel dafür, IRM als Bestandteil eines größeren Produkts zu behandeln.
Aber: Es gibt gute Gründe, warum spezialisierte IRM-Plattformen wie ilert, PagerDuty und xMatters existieren – und weiterhin wachsen. Incident Response ist eine besondere Herausforderung, die Mensch und System in kritischen Momenten miteinander verbindet. Wenn IRM nur ein Feature ist, wird diese Komplexität schnell unterschätzt. Der eigentliche Mehrwert einer IRM-Plattform liegt darin, als zentrale Dispatcher-Instanz zwischen Menschen und Maschinen zu agieren – genau dann, wenn es zählt. Und das geht weit über das hinaus, was ein Zusatzmodul leisten kann.
Ein Vergleich: Niemand würde „Kundensupport“ bloß als Feature seines E-Mail-Dienstes betrachten – auch wenn Support über E-Mail möglich ist. Unternehmen setzen gezielt auf spezialisierte Support-Plattformen. Genau deshalb braucht auch Incident Response ein eigenes, dafür entwickeltes Tool.
Warum Incident Response Management eine eigene Kategorie bleibt
Aus meiner Sicht bleibt IRM aus mehreren Gründen eine eigenständige Kategorie:
Zentrale Alert-Weiterleitung. Eine echte IRM-Plattform fungiert als zentrale Stelle für alle kritischen Alerts – unabhängig von ihrer Quelle. Sie sammelt Signale aus verschiedensten Monitoring-, Observability- und Automatisierungstools und stellt sicher, dass sie zur richtigen Zeit bei den richtigen Personen landen. Diese „Single Pane of Glass“ für Incidents ist kaum zu erreichen, wenn Incident Management über verschiedene Module in verschiedenen Systemen verteilt ist. Weder JSM noch Compass allein können diese zentrale Dispatcher-Rolle abbilden – dafür braucht es ein spezialisiertes IRM-Tool.
Spezialisierte On-Call- und Eskalations-Workflows. IRM-Plattformen bieten tiefgehende Funktionen wie Bereitschaftsplänen, Rotationsmanagement, mehrstufige Eskalationen, automatische Stakeholder-Benachrichtigungen und Post-Mortem-Dokumentation. Diese Funktionen sind nicht nebensächlich – sie sind das Herzstück. Wird Incident Response nur als Feature betrachtet, sind solche Funktionen oft eingeschränkt oder versteckt. Ein eigenständiges IRM-System fokussiert sich gezielt auf kurze Reaktionszeiten und effiziente Zusammenarbeit im Ernstfall.
Vendor-neutrale Integrationen. Ein entscheidender Punkt: IRM-Plattformen müssen mit einer Vielzahl an Tools funktionieren – Monitoring-Systeme, Observability-Plattformen, ITSM, Chat-Tools, CI/CD-Pipelines und mehr. Wer auf ein IRM-Feature innerhalb einer Suite setzt, läuft Gefahr, sich in einem geschlossenen System zu verlieren. Eine eigenständige IRM-Plattform ist von Grund auf vendor-neutral. Bei ilert bedeutet das z. B., dass wir bewusst kein Monitoring-Tool mehr anbieten – um unsere Unabhängigkeit zu wahren und mit allen Monitoring-Anbietern partnerschaftlich zusammenzuarbeiten.
Leichte Ergänzung zur bestehenden Toolchain. Ein IRM-Tool ersetzt kein Monitoring und kein ITSM – es ergänzt sie. Viele Unternehmen kombinieren z. B. ServiceNow für Dokumentation und Compliance mit ilert für Paging und Koordination in Echtzeit. Während ServiceNow strukturierte ITIL-Prozesse abbildet, sorgt ilert für schnelles, menschliches Eingreifen. Über 100 Integrationen mit Monitoring-, Observability-, ITSM- und Chat-Tools machen diese flexible Orchestrierung möglich.
Fokus und Innovationskraft. Wenn IRM eine eigenständige Kategorie bleibt, kann auch echte Innovation stattfinden. Die Teams hinter spezialisierten Tools arbeiten fokussiert an genau einem Problem: effektives Incident Response. Das führt zu besseren Nutzererlebnissen, intelligenterem Alert Routing (inkl. KI), verbesserten Status Pages und tiefergehender Analytik – alles passgenau für Incident Management.
Ein konkretes Beispiel für IRM als eigenständige Kategorie ist unsere Produktstrategie bei ilert. Unser Ziel ist es, bestehende Toolchains zu ergänzen, nicht zu ersetzen. Deshalb haben wir unsere Uptime-Monitoring-Funktion eingestellt – um konsequent integrationsfreundlich und neutral zu bleiben.
In unserer Ankündigung dazu erklärten wir: Nur so können wir vermeiden, mit Monitoring-Partnern in Konflikt zu geraten. Wir wollen nie einseitig eine bestimmte Datenquelle bevorzugen – unsere Aufgabe ist es, alle Alerts zuverlässig an die richtigen Personen weiterzuleiten.
Dieses integrative Denken zahlt sich aus: ilert funktioniert mit bestehenden Systemen, ohne dass Nutzer:innen Tools wechseln oder einschränken müssen. Über 100 Integrationen – z. B. mit Jira, ServiceNow, Datadog, CloudWatch, Slack und Microsoft Teams – belegen das. Ehemalige Opsgenie-Kund:innen schätzen genau diese Offenheit und den klaren Fokus von ilert.
Die IRM-Plattform als zentrale Dispatcher-Instanz
Im Kern ist eine Incident Response Management-Plattform der zentrale Dispatcher zwischen Menschen und Systemen – insbesondere während Ausfällen oder kritischen Ereignissen. Die meisten Unternehmen verfügen über Monitoring-Tools, die Probleme erkennen, und Ticketing-Systeme, die Aufgaben erfassen und zuweisen. Doch es ist die IRM-Plattform, die diese Lücke in Echtzeit schließt – sie sorgt dafür, dass um 2 Uhr morgens das richtige Telefon klingelt und das Team sofort reagieren kann. Sie koordiniert Menschen (über Alerts, Eskalationen und Zusammenarbeit) auf Basis von Maschinensignalen.
Diese Rolle ist einzigartig. Wenn man Incident Response ausschließlich über ein Monitoring-Tool abwickeln will, erhält man zwar Alerts, lässt jedoch wichtige menschliche Workflows wie Eskalationen oder teamübergreifende Kommunikation außen vor. Versucht man dasselbe rein über ein ITSM-Tool, verliert man oft an Geschwindigkeit und Einfachheit – weil Notfälle zu Tickets werden, was Verzögerungen und Bürokratie mit sich bringen kann.
Der wahre Wert einer IRM-Plattform zeigt sich darin, wie gut sie bestehende Investitionen verbindet und beschleunigt: Monitoring wird handlungsfähiger, On-Call-Teams effektiver, und der gesamte Incident-Prozess transparenter. Und all das, ohne dass man seine bestehenden Tools für Observability oder ITSM ersetzen muss. Genau deshalb sehe ich IRM als eigenständige Säule im Tech-Stack – als eine Art „Mission Control“, die neben Observability und ITSM steht, nicht in ihnen.
Abschließende Gedanken
Die Frage „Kategorie oder Feature?“ ist wichtig – besonders in einer Zeit, in der Plattformen sich rasant weiterentwickeln. Im Fall von Incident Response Management zeigen meine Erfahrung und die Gespräche mit Kund:innen klar: IRM bleibt eine eigenständige Kategorie.
Die Bedeutung von Incidents ist zu hoch, die Zahl notwendiger Integrationen zu groß und die spezifischen Workflows zu komplex, um IRM als nachgelagertes Feature oder Checkbox-Funktion zu behandeln. Stattdessen sollten wir IRM-Plattformen als ergänzende Partner zu unseren Monitoring-, DevOps- und ITSM-Tools sehen – jede mit ihrem eigenen Fokus.
Für uns bei ilert bedeutet das: Wir verfolgen konsequent das Ziel, der zuverlässigste Dispatcher of Trust zu sein – zwischen allen Systemen, die Probleme erkennen, und allen Menschen, die sie lösen. Wir integrieren. Wir orchestrieren. Und wir bleiben vendor-neutral, damit sich unsere Nutzer:innen auf eine Plattform verlassen können, die Incident Response in den Mittelpunkt stellt.
In einer Welt, in der sich alles – von Cloud-Diensten bis Ticketing-Systemen – immer weiter verzweigt, liegt großer Wert in Spezialisierung. Incident Response Management ist genau das: eine eigenständige Disziplin und Plattform, die sicherstellt, dass kritische Vorfälle so schnell wie menschlich (und technologisch) möglich behoben werden.
Hoppla! Beim Absenden des Formulars ist etwas schief gelaufen.
Unsere Cookie-Richtlinie
Wir verwenden Cookies, um Ihre Erfahrung zu verbessern, den Seitenverkehr zu verbessern und für Marketingzwecke. Erfahren Sie mehr in unserem Datenschutzrichtlinie.







.png)






.png)



.png)





































